LLVM
了解
简单来说,可以将 LLVM 理解为一个现代化、可拓展的编译器。
so混淆有代表性的就是ollvm,它是基于LLVM诞生的一款工具。
LLVM广义上是包含了很多模块的编译器框架。
在这里狭义上指的是llvm项目中的llvm core和clang子模块。
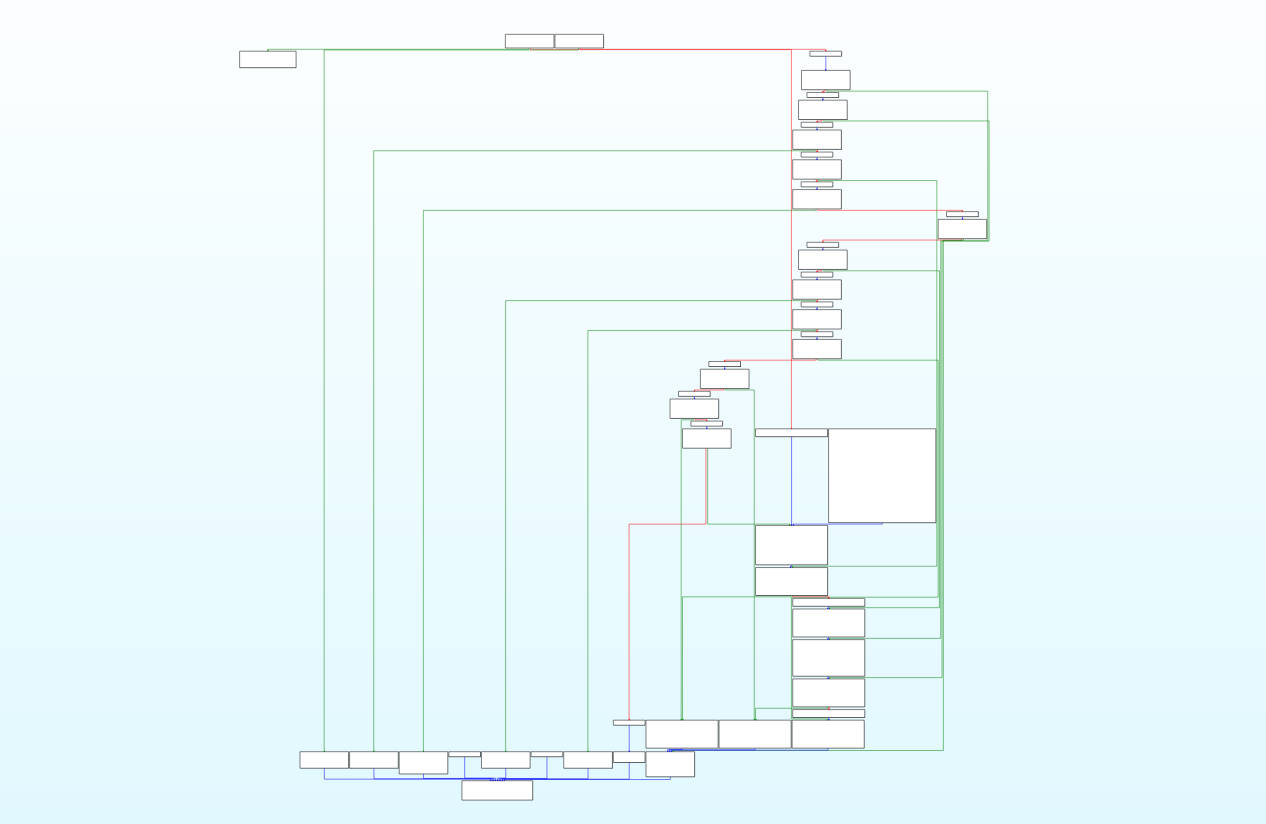
GCC与LLVM编译流程对比
GCC分为三个模块:前端、优化器和后端
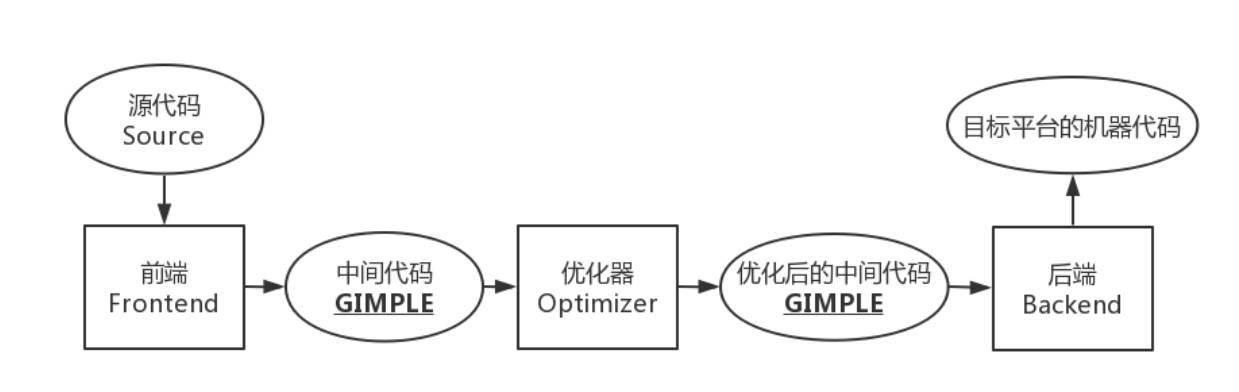
LLVM 本质上也是三段式:
示例
相对于 GCC ,LLVM 有如下优势:
- 模块化:LLVM 是高度模块化设计的,每一个模块都可以从 LLVM 项目中抽离出来单独使用。而 GCC 虽然也是三段式编译,但各个模块之间是难以抽离出来单独使用的。
- 可拓展:LLVM 为开发者提供了丰富的 API ,例如开发者可以通过 LLVM Pass 框架干预中间代码优化过程,并且配备了完善的文档。虽然 GCC 是开源的,但要在 GCC 的基础上进行拓展门槛很高、难度很大。
OLLVM
OLLVM(Obfuscator-LLVM)是一个基于LLVM框架的开源代码混淆工具,旨在通过修改程序的中间表示(IR)增加代码的复杂性,从而提升逆向工程的难度。
OLLVM是LLVM编译器框架的一个分支,通过插入混淆逻辑到编译过程中,生成难以理解和分析的二进制代码。
原理:在LLVM的中间表示(IR)层面进行代码转换,保留程序功能但改变代码结构,适用于C/C++等LLVM支持的语言。
代码混淆
代码混淆的主要目的是防止或至少是阻碍对代码的未授权分析和修改。
代码混淆可以提高代码的安全性,但它不能提供绝对的保护。
函数
函数是代码混淆的基本单位。一个函数由若干基本块组成,有且仅有一个入口块,可能有多个出口块。
一个函数可以用一个控制流程图(Control Flow Graph)表示。
基本块
基本块由一组线性指令组成,每一个基本块都有一个入口点(第一条执行的指令)和一个出口点(最后一条执行的指令,即终结指令)。
终结指令要么跳转到下一个基本块,要么从函数返回。
指令
指令(Instruction)是LLVM中间表示(IR)的最小执行单元,对应程序中的原子操作(如算术运算、内存访问、控制流跳转等)。每条指令属于某个基本块,并严格按顺序执行(除非被终结指令中断)。
控制流
控制流代表了一个程序执行过程中可能遍历到的所有路径。
通常情况下,程序的控制流很清晰地反映了程序的逻辑,但经过混淆的控制流会使得人们难以分辨正常逻辑。
常见混淆
不透明谓词
不透明谓词是一种在编译时即可确定结果(真或假)的条件表达式,但其逻辑对逆向分析者而言是“不透明”的(难以静态推断)。它被插入到代码中,用于生成虚假控制流分支,干扰逆向工程。
特点
静态确定性:编译时即可计算结果(如 1 > 0 永真,2 + 2 = 5 永假)。
动态隐蔽性:通过复杂计算或依赖上下文数据,伪装成动态条件。
不可达路径:插入与程序逻辑无关的分支,增加分析复杂度。
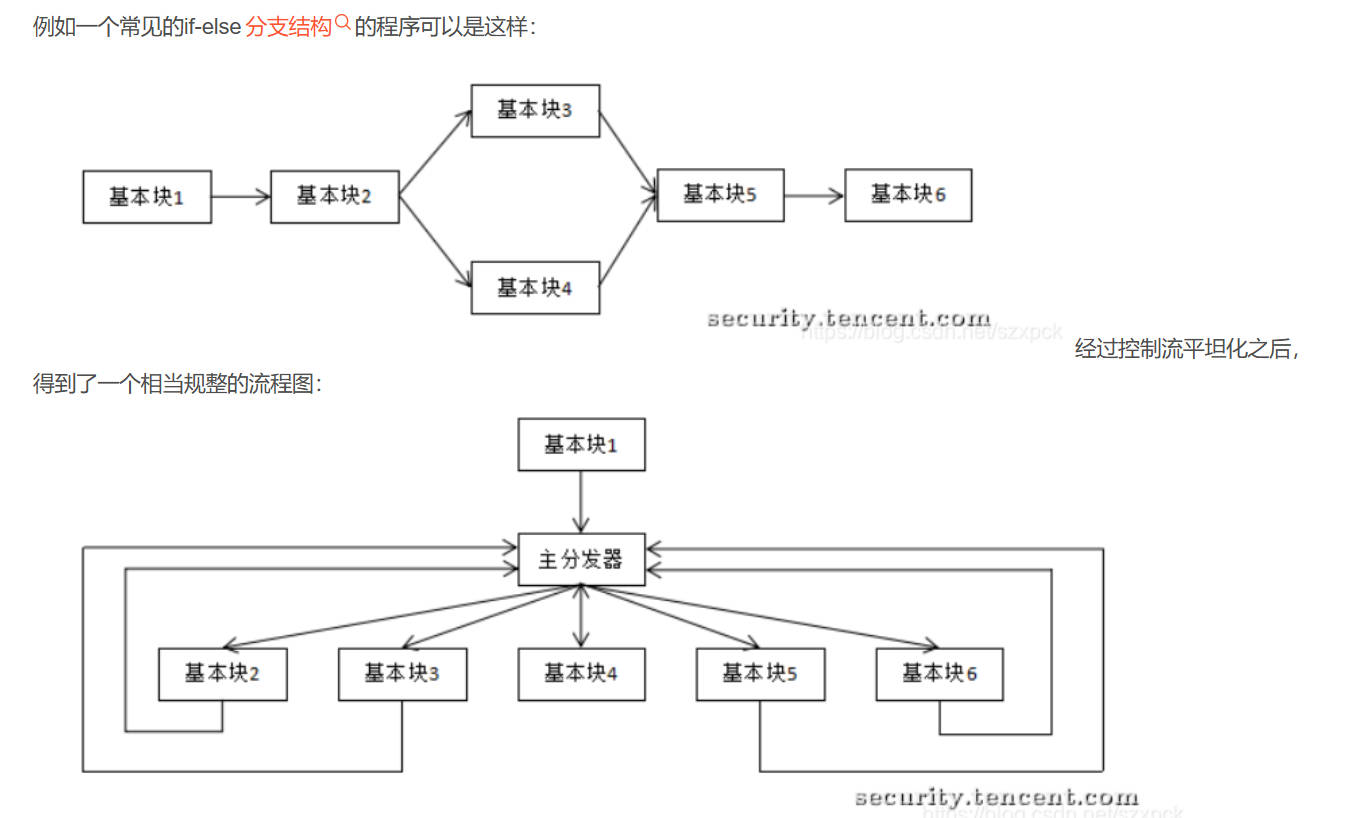
控制流平坦化
通过破坏代码的原始控制流结构,将其转换为“平坦化”的状态机形式。
其核心目标是隐藏程序逻辑的跳转关系,使逆向工程难以恢复原始执行流程。
特点
统一入口/出口:所有基本块通过一个“分发块”(Dispatcher)调度。
状态驱动:通过变量(状态值)决定下一个执行的基本块。
消除结构化特征:原始分支(如if-else、循环)被替换为跳转表或状态切换。
虚假控制流
虚假控制流是一种通过插入永真永假条件分支或冗余跳转来干扰控制流分析的代码混淆技术。其核心目标是增加控制流图(CFG)的复杂度,使得逆向工程难以区分真实逻辑与无效代码。
以基本块为单位,通过一个主分发器来控制程序的执行流程。
特点
无效分支:插入的条件分支在运行时永远不会被执行(如 if (1 > 0) 永真分支)。
逻辑干扰:破坏基本块之间的直接跳转关系,生成“蜘蛛网”式CFG。
低开销:相比控制流平坦化,性能影响较小。
指令替换
指令替换是一种通过将简单指令替换为等效但更复杂的指令序列的代码混淆技术。其核心目标是增加代码的语义复杂度,使得逆向工程难以理解程序逻辑,同时保持功能不变。
花指令去除
无法解析的跳转地址1
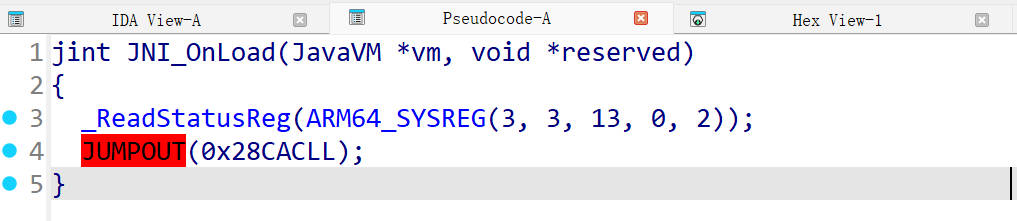
转换为汇编代码如下
通过BR指令跳转到X5存储的地址处
1 | LOAD:0000000000028C48 FF 83 01 D1 SUB SP, SP, #0x60 |
经计算X5的值为0x28CAC

0x28CAC地址处是一堆数据,是IDA未能正确分析所致
使用U取消定义,光标移动到0x28CAC地址处,使用C重新识别为代码
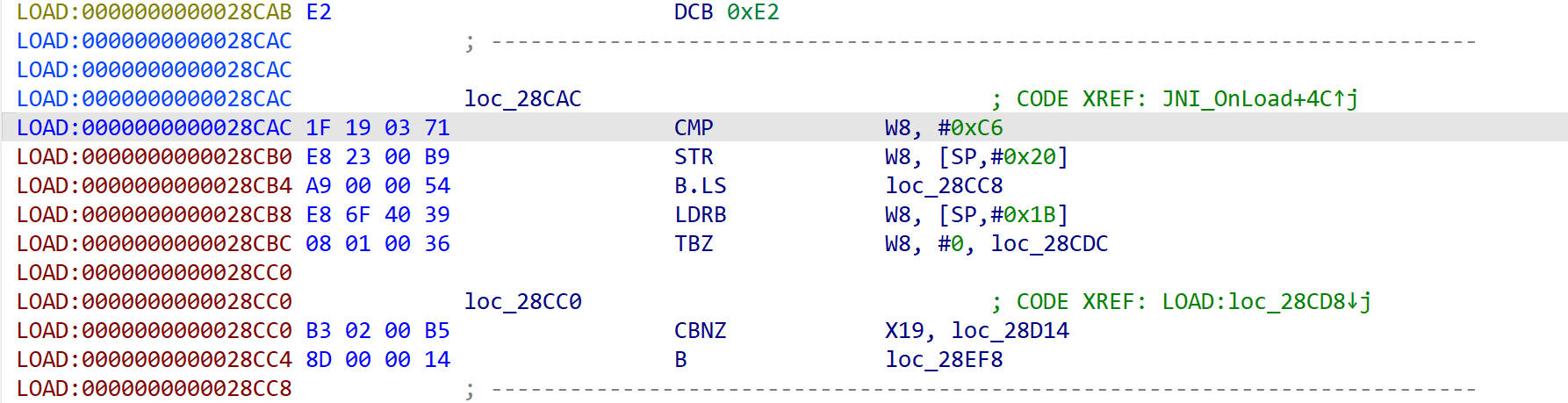
回到BR指令处进行patch
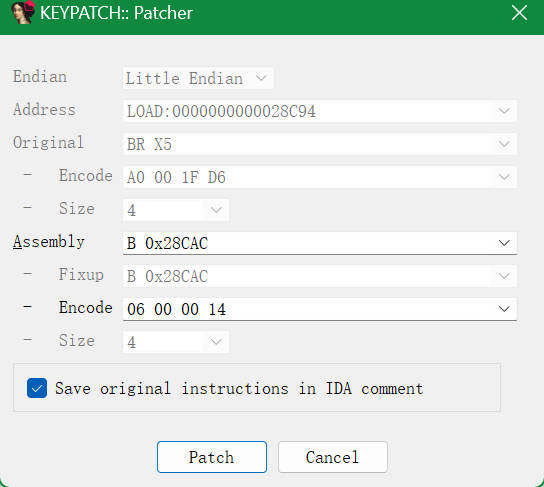
patch完成之后重新反编译,如下还是出现了无法识别的指令
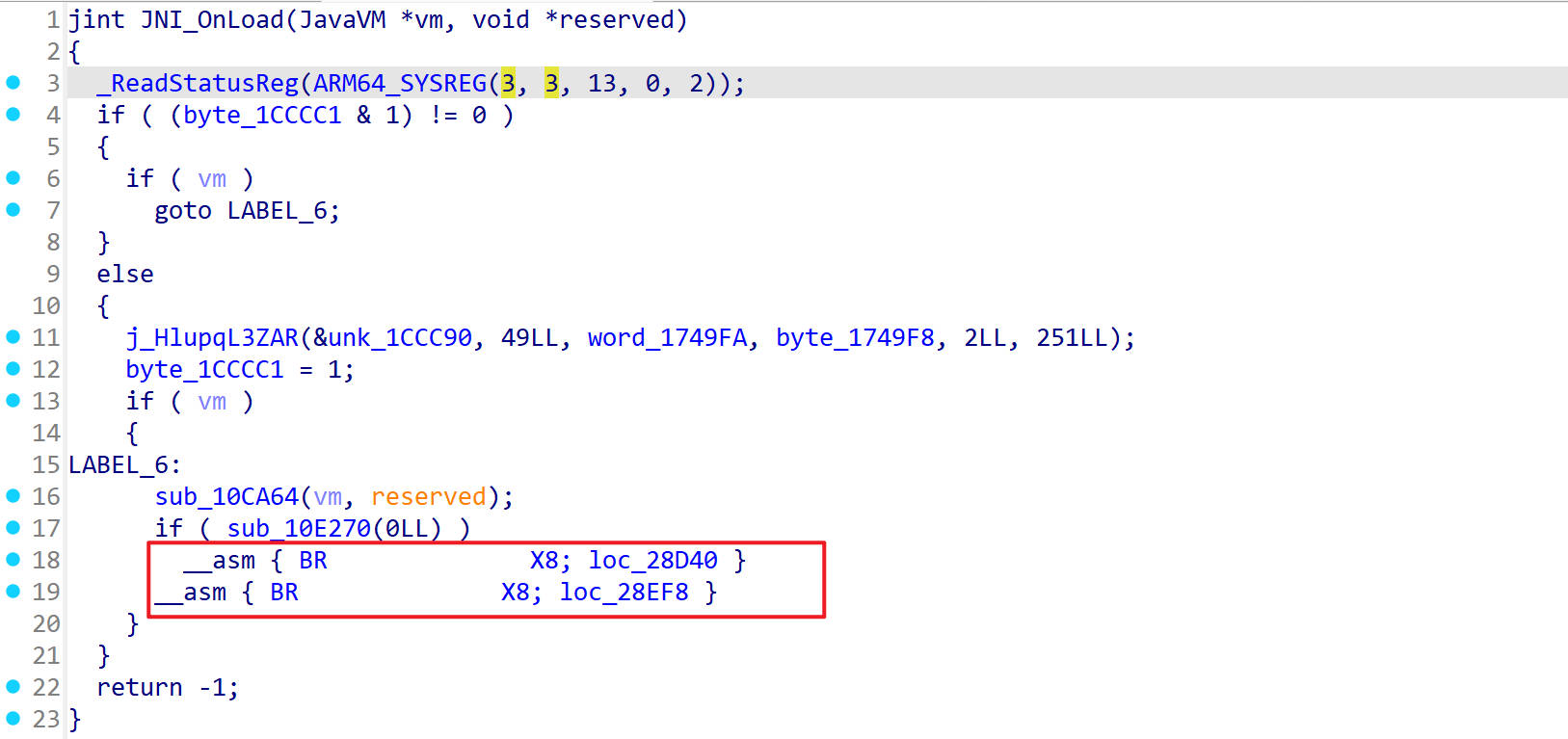
这里把BR指令改为B指令后面跟上跳转的地址
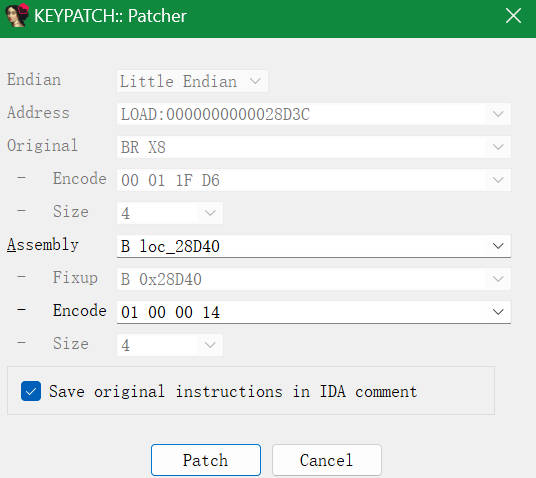
后面出现很多BR 寄存器的指令,重复同样的操作进行修正,就可以看到正常的函数逻辑。
无法解析的跳转地址2
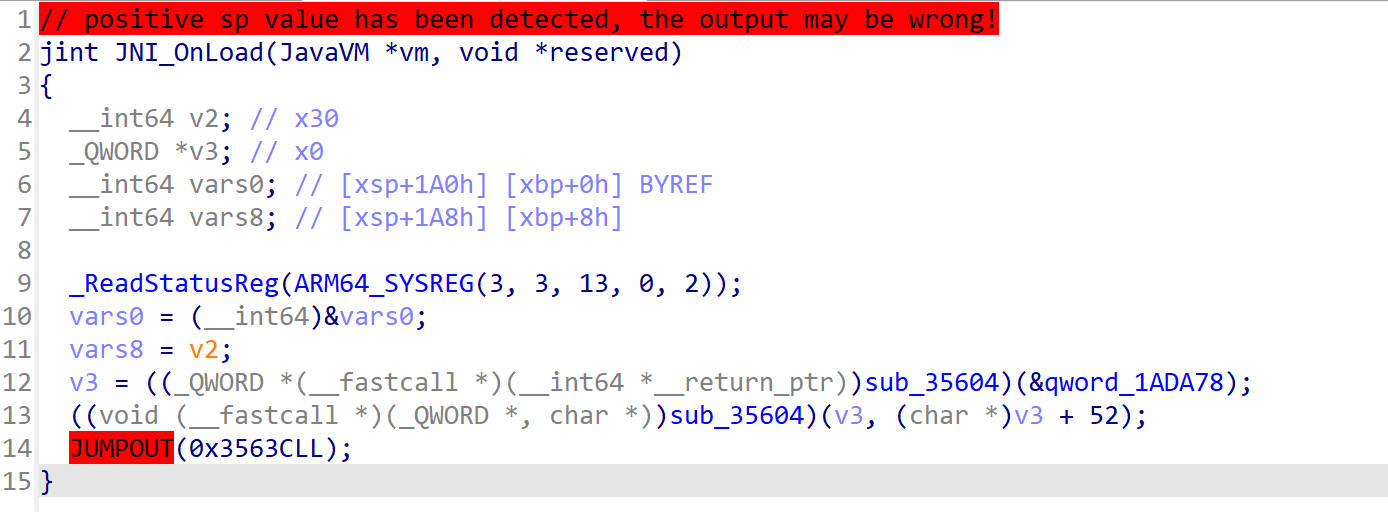
这里的JUMPOUT是在patch修正之后出现的,这时候可以通过重新分析程序或者保存patch文件重新用IDA打开。
无法解析的跳转地址3
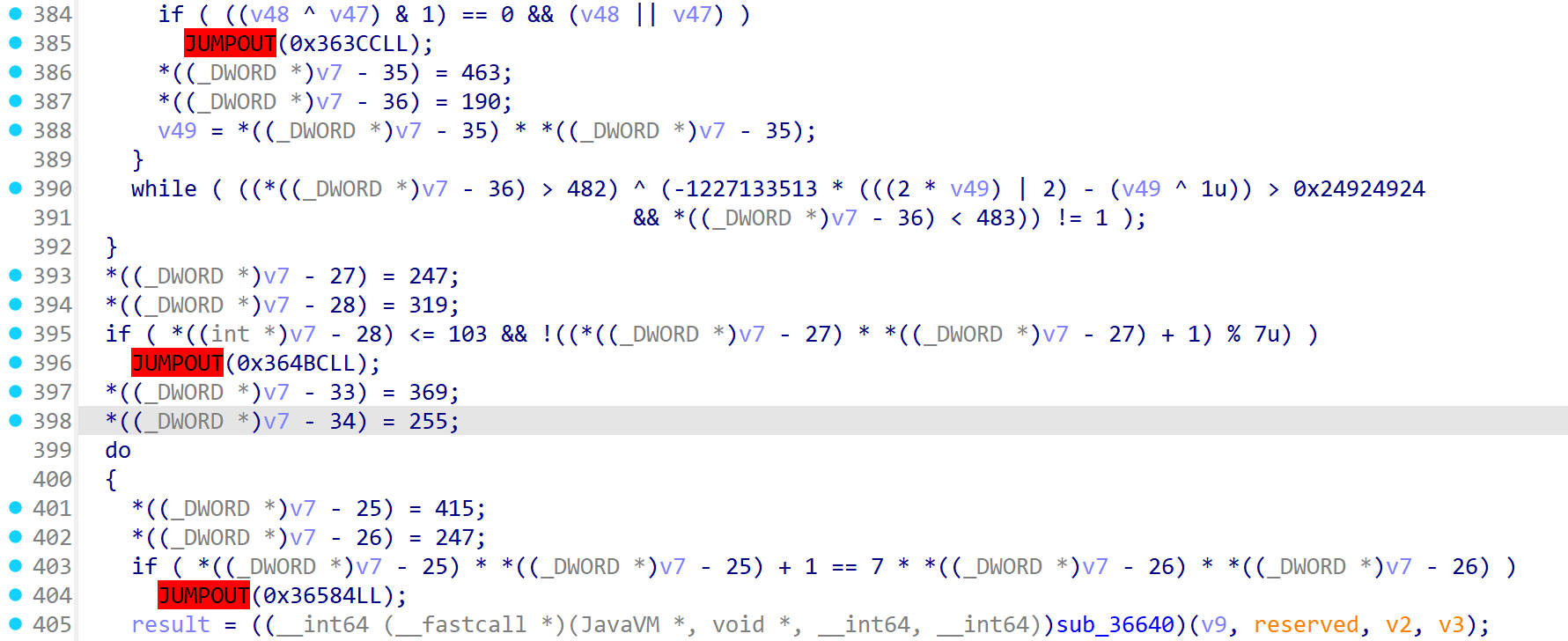
这里的JUMPOUT是重新分析程序后出现的,转换为汇编代码之后,取消定义,重新生成代码失败了
那么可能是这里本身就是数据,IDA出错了
这里看到数据上方有一个CBZ指令
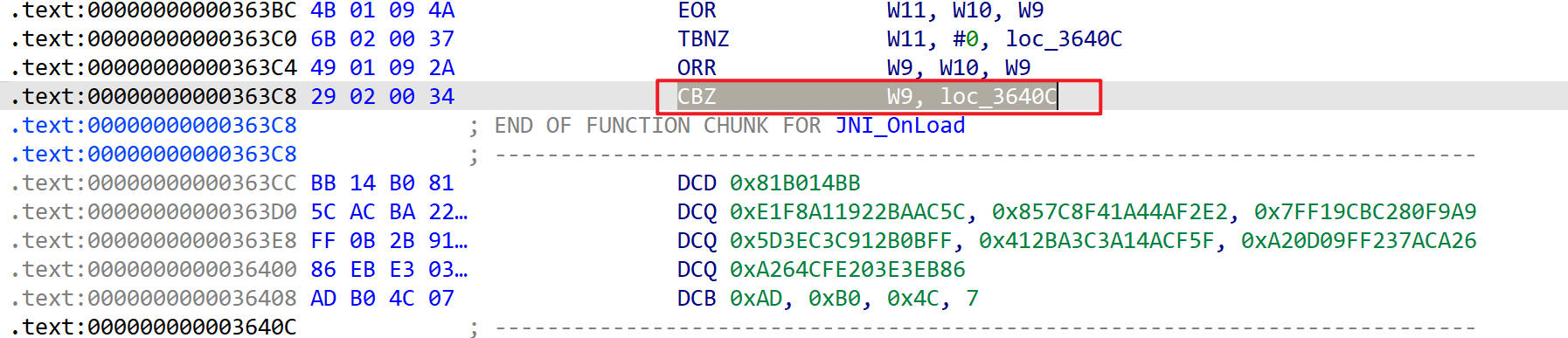
这里的CBZ指令从逻辑上来看是会跳转到loc_3640C的,程序是不会执行到这一块存放数据的内存的,却能影响到IDA的分析。
把CBZ指令改为B指令
堆栈不平衡

在汇编代码中观察SP
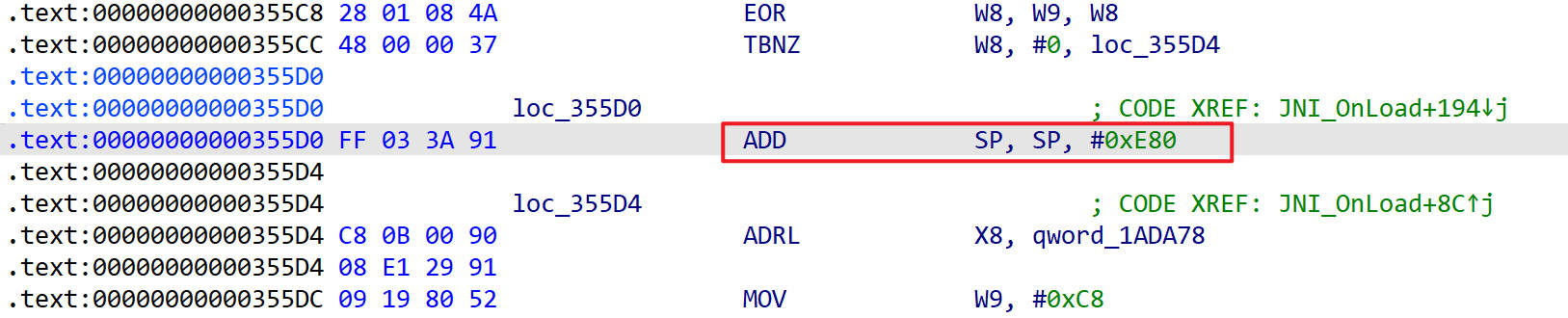
这里栈出错了,在函数内部出现栈增加,而且这里增加的长度要大于栈本身的长度,导致出错了。
把这行汇编指令nop掉,后面还会有很多这样的影响栈的指令,全都要手动nop掉,nop完了之后重新分析程序,函数就恢复正常了。
反虚假控制流
分析如下方法jiance_xp_frida()
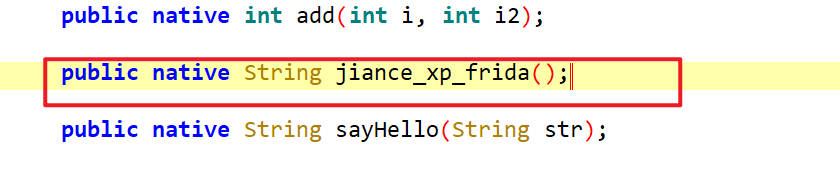
在IDA中是如下样子
unidbg模拟执行函数
根据函数的地址范围,打印指令的偏移地址并存入文件中
1 | emulator.getBackend().hook_add_new(new CodeHook() { |
然后可以使用IDAPython脚本把这些地址添加高亮。
手动还原控制流平坦化
demo中的目标函数
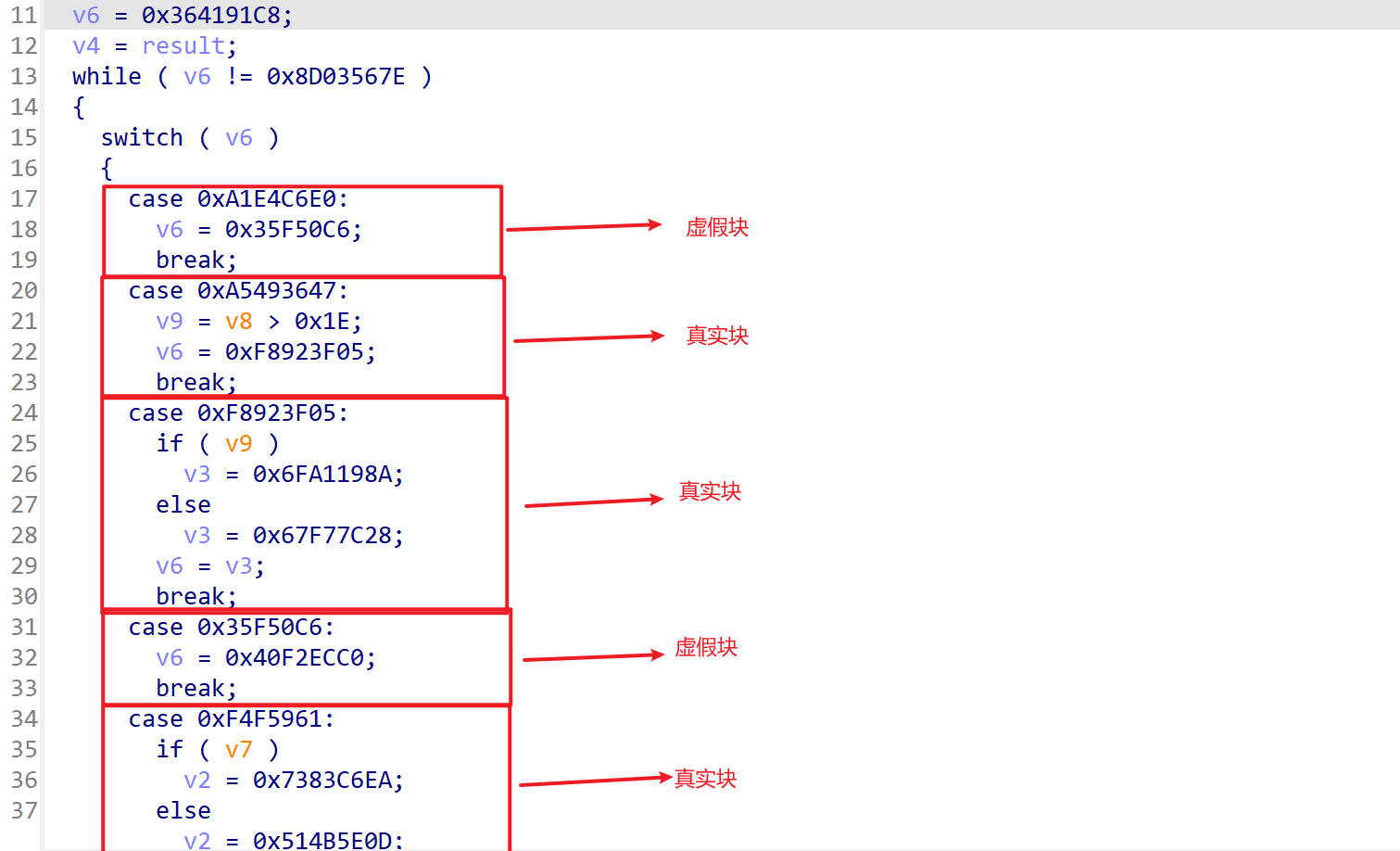
转换为汇编代码,找出所有真实块以及对应的汇编地址,标准的ollvm虚假块中一般只有简单的修改v6的值,其他的基本都是真实块,
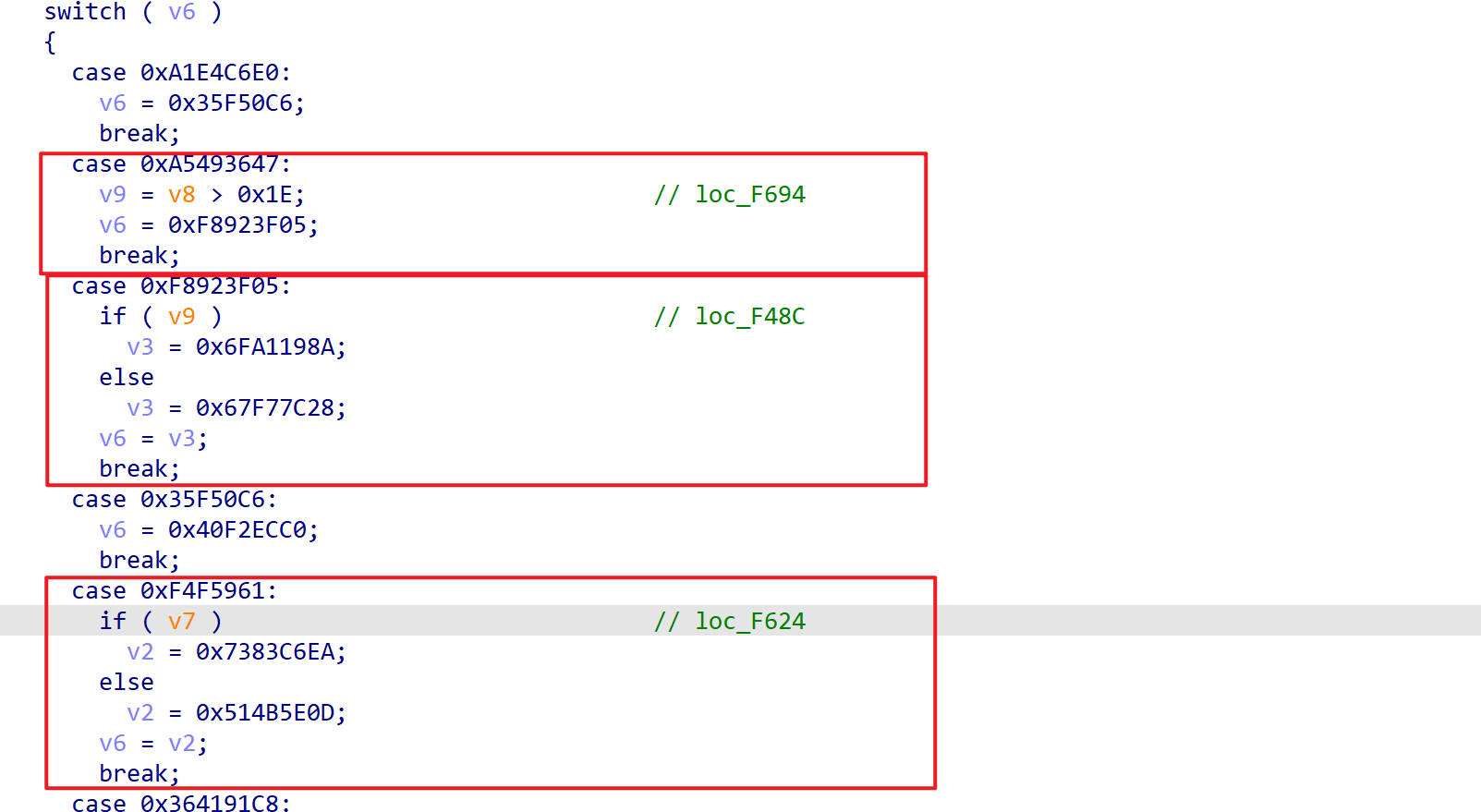
通过汇编代码查看每个真实块的label标签,在每个真实块后面进行注释,如下
找出所有真实块的地址后,接着就是顺着逻辑将他们全部串联起来。
从函数开始的地方往下分析,通过patch修改函数流程
如下是修正之后的流程图